Review of Optical Neural Networks
One of the most influential papers on diffractive deep neural networks (D2NNs) is “All-optical machine learning using diffractive deep neural networks” [1] .
In this lecture, we reproduce the core D2NN architecture from [1] in SVETlANNa and train it on MNIST using the same physical design principles. The goal is to understand how a conventional neural-network operation can be mapped to optical propagation and phase modulation.
Linear Diffractive Neural Network (D2NN)
Theory
From conventional neural networks to optical layers
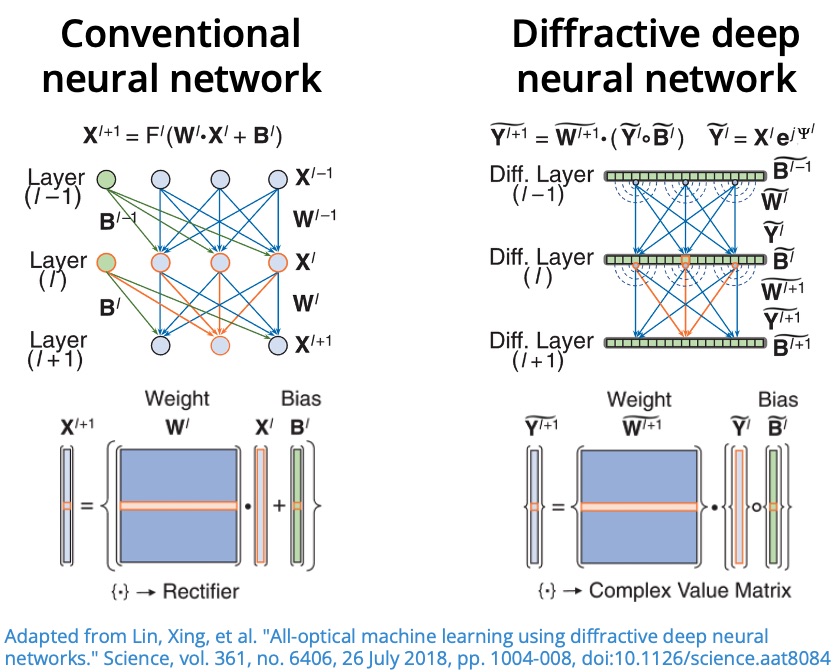
For a classical neural network, the output of layer is
where:
- is the weight matrix,
- is the bias vector,
- is a nonlinear activation function.
Stacking layers gives a composition of linear transformations and nonlinearities.
In a D2NN, the trainable part is implemented by diffractive phase masks, and layer-to-layer coupling is performed by free-space propagation. At each optical layer:
- The complex field is multiplied by a phase mask.
- The modulated field propagates to the next plane.
This can be written as
where:
- is the complex optical field at layer ,
- is the phase-only modulation at layer ,
- is the free-space propagation operator,
- denotes convolution induced by propagation,
- denotes element-wise multiplication.
Therefore, the trainable parameters are the phase values of each diffractive layer.
Implementation Plan
To implement the D2NN from [1] , we will follow this workflow:
- Define physical and simulation parameters (wavelength, layer resolution, neuron size, axial distances).
- Prepare MNIST and encode each image as an input optical field.
- Build the optical model in SVETlANNa:
- define detector regions at the output plane (one region per class),
- create a sequence of diffractive layers separated by free-space propagation.
- Define the training pipeline.
- Train, validate, and visualize the learned optical system.
Parameters Reported in the Original Papers
Below are the key experimental and simulation settings reported by the authors.
From [1] :
- Task: MNIST digit classification ( to ).
- Architecture: five-layer phase-only .
- Dataset split used in training: training and validation samples.
- Illumination frequency: (continuous-wave).
- Neuron size: .
- Axial spacing between successive layers: .
- Detector size: .
- Batch size: .
- Optimizer: Adam.
Additional clarifications from [2] :
- Neuron size expressed relative to wavelength: approximately .
- Layer dimensions: neurons per diffractive layer.
- Detector normalization at the output plane:
where is the total optical intensity measured by detector .
- Optimization details: Adam with learning rate .
These values define a practical baseline for reproducing the published D2NN behavior in SVETlANNa.
Diffractive Recurrent Neural Network (D-RNN)
In this lecture, we implement the recurrent diffractive architecture proposed in [1] for human action recognition on the Weizmann dataset .
The main objective is to show how temporal memory, usually handled by recurrent neural networks, can be realized in an optical diffractive system.
Theory
Why recurrence is needed
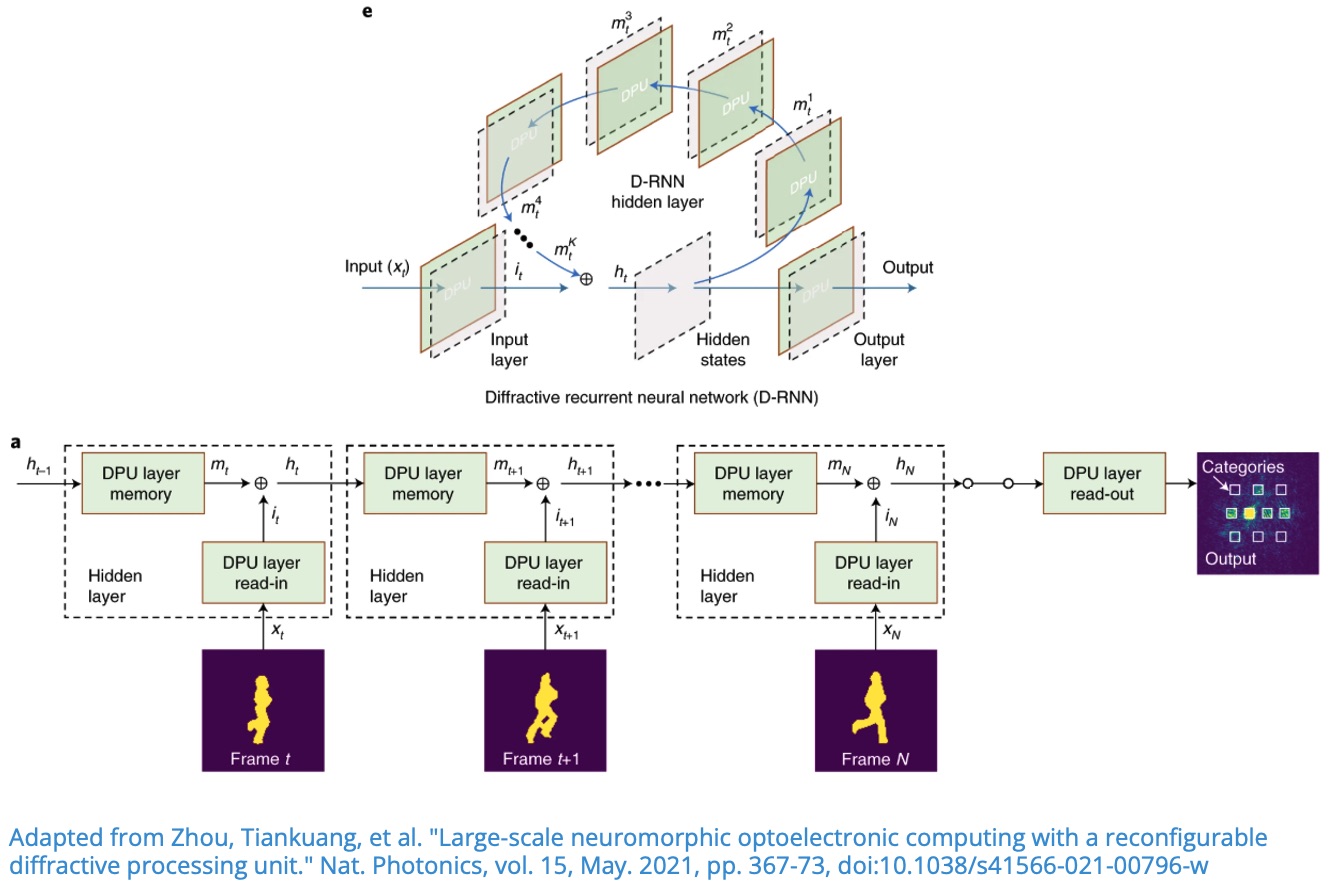
For sequential inputs (for example, video frames), the prediction at time should depend not only on the current frame , but also on what the system has seen before. This is the core idea behind recurrent models.
In a diffractive recurrent neural network (D-RNN), the optical layers are reused across time steps. The model maintains a hidden optical state that combines:
- memory from the previous state ,
- information from the current input .
The recurrence is written as
where:
- is the memory mapping,
- is the input (read-in) mapping,
- controls the memory-input tradeoff.
Before the detectors, a read-out mapping is applied:
In our optical implementation, , , and are realized using diffractive layers and free-space propagation.
For three time steps, the computation is:
Implementation Plan
To implement the D-RNN from [1] , we follow this workflow:
- Define physical and simulation parameters (wavelength, grid size, neuron size, propagation distances).
- Prepare the Weizmann dataset and convert videos into short frame sequences.
- Build the optical model in SVETlANNa:
- define detector regions at the output plane (one region per class),
- implement read-in, memory, and read-out diffractive mappings.
- Define the training pipeline for sequence-wise forward passes and loss computation.
- Train, validate, and visualize classification performance and optical fields.
Parameters Reported in the Original Paper
Key settings reported by the authors in [1] :
- Input masks were extracted by background subtraction; provided mask data include both original and aligned masks.
- Mask resolution: .
- Data split: six subjects ( videos) for training and three subjects ( videos) for testing.
- Sequence construction: each video is split into sub-sequences of three frames with a frame interval of two.
- Number of detector regions equals number of classes:
- ten regions for MNIST, Fashion-MNIST, and Weizmann,
- six regions for KTH,
- each output region has width .
- Recurrent state update:
with as the memory mapping, as the input mapping, and controlling the relative contribution of memory and current input.
These settings provide a practical baseline for reproducing D-RNN experiments in SVETlANNa.
Convolutional Diffractive Network
In this lecture, we implement the Convolutional Diffractive Network introduced in “Optical Diffractive Convolutional Neural Networks Implemented in an All-Optical Way” [1] .
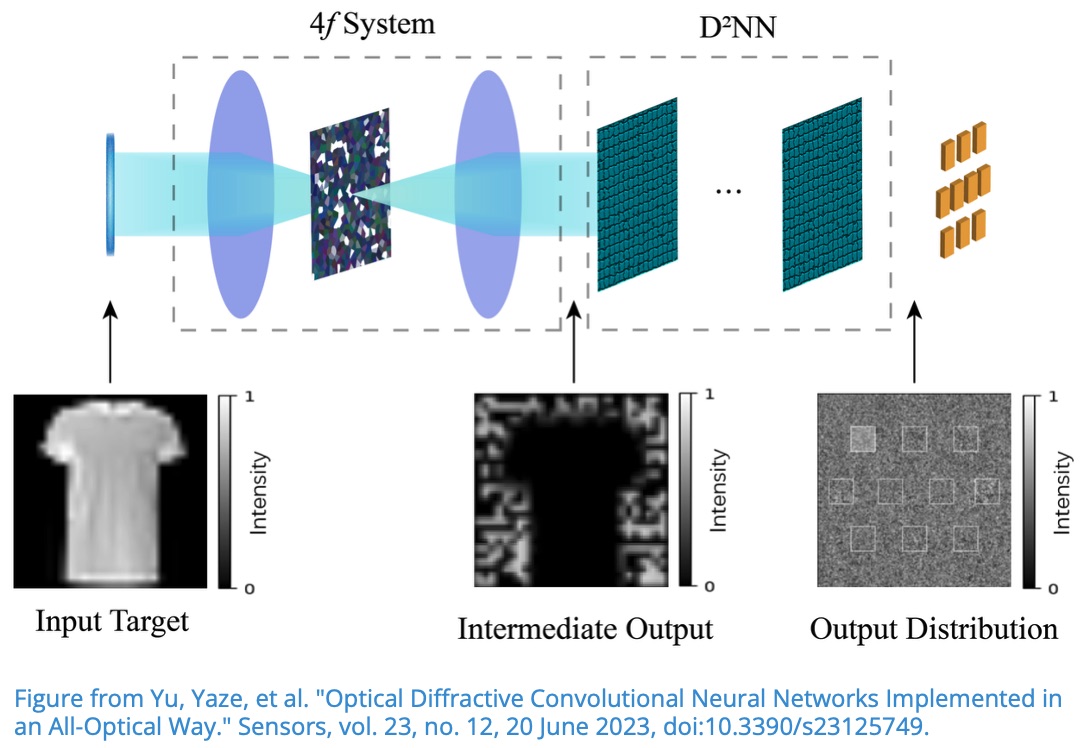
The key idea is to perform the convolution operation optically with a 4f system, and then feed the result into a trainable diffractive network for classification.
Theory
Convolution in the spatial domain is equivalent to multiplication in the Fourier domain:
where denotes the Fourier transform.
This identity is especially useful in optics because a lens can perform a Fourier transform. In a 4f optical setup:
- The first lens transforms the input field into .
- A filter in the Fourier plane applies multiplication by .
- The second lens performs the inverse transform, producing the convolution result.
So the optical system computes:
In this lecture, the Fourier-plane diffractive mask that defines the convolution kernel is fixed. The output of the 4f convolutional stage is then propagated through a trainable diffractive deep neural network (D2NN), which learns the final classification mapping.
Implementation Plan
To implement the convolutional diffractive architecture from [1] , we follow this workflow:
- Define physical and simulation parameters (wavelength, layer resolution, neuron size, axial distances).
- Prepare MNIST and encode each image as an input optical field.
- Build the optical model in SVETlANNa:
- define detector regions at the output plane (one region per class),
- define fixed convolution kernels in the Fourier plane,
- create a 4f system to perform optical convolution,
- add trainable diffractive layers with free-space propagation.
- Define the training pipeline (forward propagation, detector readout, loss, optimization).
- Train, validate, and visualize the learned optical system.
Parameters Used in This Lecture
Paper [1] does not provide all low-level physical parameters needed for a full implementation. For reproducibility in SVETlANNa, we reuse compatible physical settings from [2] , as in previous lectures.
One important preprocessing detail is:
- the input image of size is zero-padded to .